
时空壶发布 W4:用「硬核」技术,打赢一场 AI 翻译的「标准」之战
时空壶发布 W4:用「硬核」技术,打赢一场 AI 翻译的「标准」之战翻译耳机这个新赛道,当巨头还在做「功能」,这家公司已在定义「体验」。
来自主题: AI资讯
11107 点击 2025-09-08 10:35
 搜索
搜索
翻译耳机这个新赛道,当巨头还在做「功能」,这家公司已在定义「体验」。
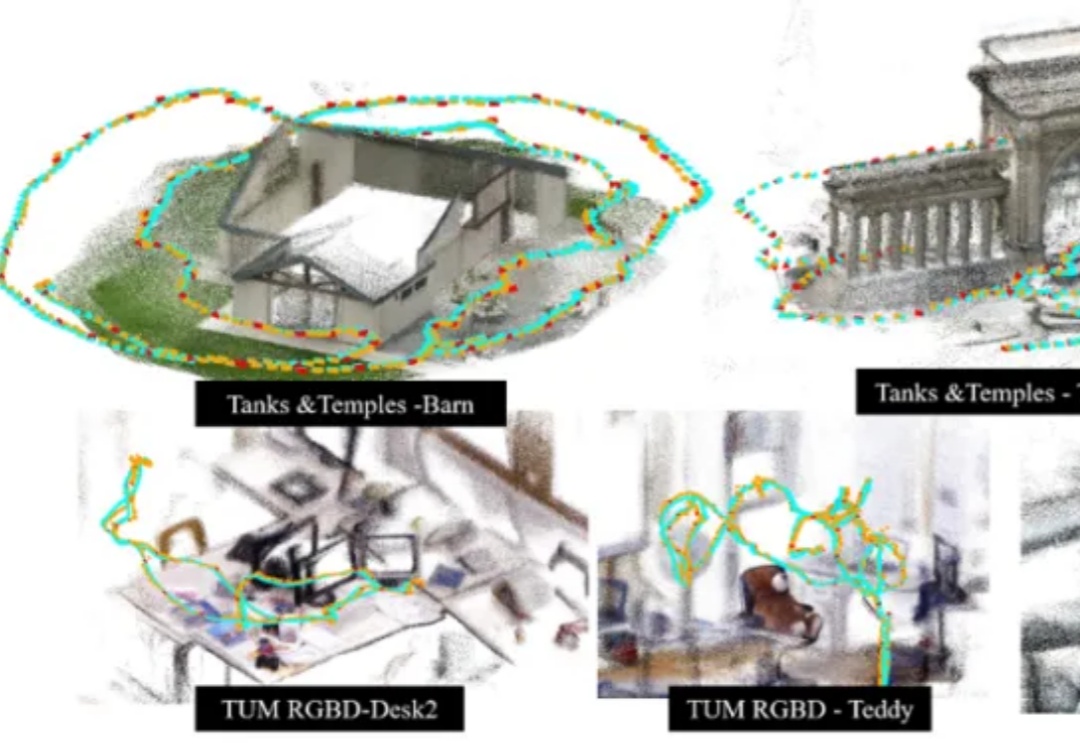
香港科技大学谭平教授团队与地平线(Horizon Robotics)团队最新发布了一项 3D 场景表征与大规模重建新方法 SAIL-Recon,通过锚点图建立构建场景全局隐式表征,突破现有 VGGT 基础模型对于大规模视觉定位与 3D 重建的处理能力瓶颈,实现万帧级的场景表征抽取与定位重建,将空间智能「3D 表征与建模」前沿推向一个新的高度。
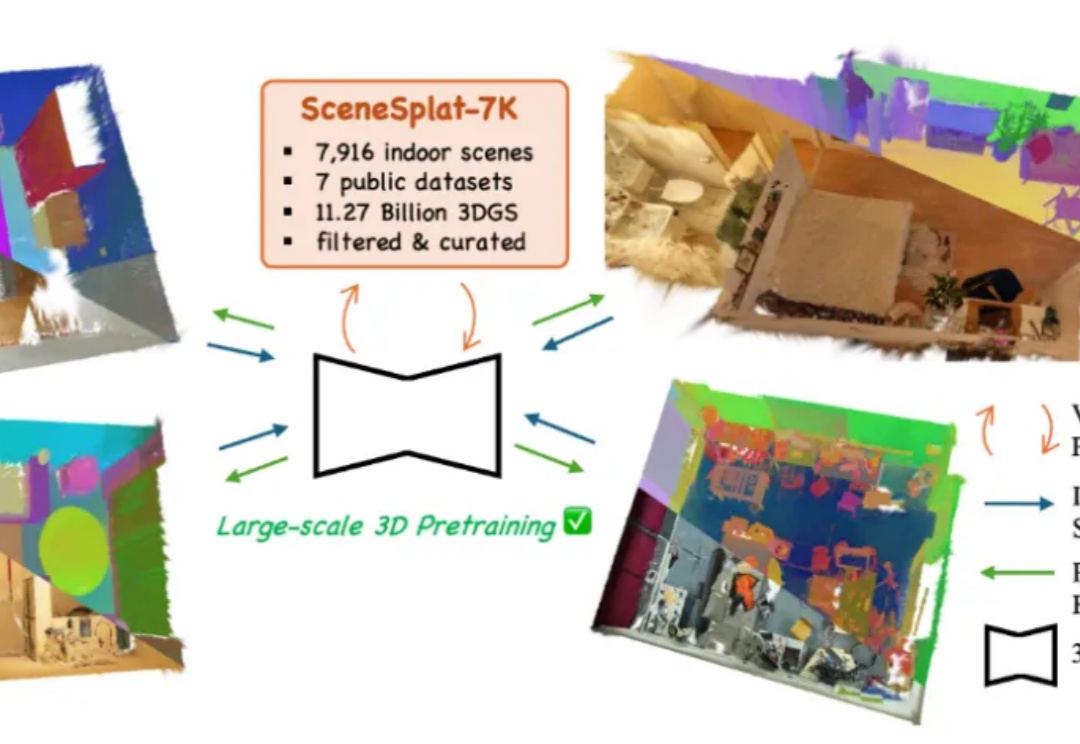
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。

最新消息,AI 初创公司 Anthropic 同意支付至少 15 亿美元,来和解一起作家集体诉讼案件。此前,这些作家联合指控 Anthropic 盗版了他们的作品来训练其聊天机器人 Claude。

OpenAI重磅结构调整:ChatGPT「模型行为」团队并入Post-Training,前负责人Joanne Jang负责新成立的OAI Labs。而背后原因,可能是他们最近的新发现:评测在奖励模型「幻觉」,模型被逼成「应试选手」。一次组织重组+评测范式重构,也许正在改写AI的能力边界与产品形态。

Lambda 收入可观,英伟达主导地位稳固,大家都有美好未来 据 The Information 最新消息称,英伟达已经与小型云服务提供商 Lambda 达成一笔总额高达 15 亿美元的合作协议,内容是前者将租赁后者搭载英伟达自研 AI 芯片的 GPU 服务器。

好家伙,我直呼好家伙。 号称「赛博白月光」的 GPT-4o,在它的知识体系里,对日本女优「波多野结衣」的熟悉程度,竟然比中文日常问候语「您好」还要高出 2.6 倍。
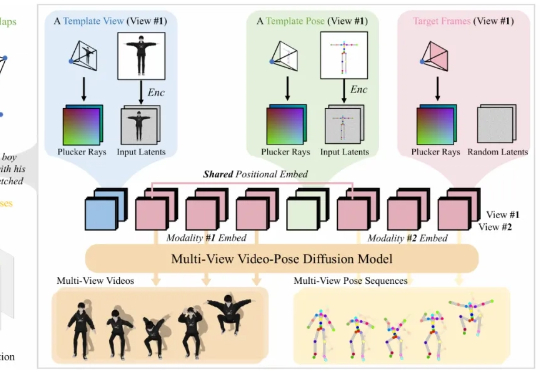
在游戏、影视制作、虚拟人和交互式内容创作等行业中,高质量的 3D 动画是实现真实感与表现力的基础。然而,传统计算机图形学中的动画制作通常依赖于骨骼绑定与关键帧编辑,这一流程虽然能够带来高质量与精细控制,但需要经验丰富的艺术家投入大量人力与时间,代价昂贵。

AI 最臭名昭著的 Bug 是什么?不是代码崩溃,而是「幻觉」—— 模型自信地编造事实,让你真假难辨。这个根本性挑战,是阻碍我们完全信任 AI 的关键障碍。
《金融时报》最新消息,OpenAI 正在和博通合作,自研一颗代号 “XPU” 的 AI 推理芯片,预计会在 2026 年量产,由台积电代工。不同于英伟达 的 GPU,这款芯片不会对外销售,而是专门满足 OpenAI 内部的训练与推理需求,用来支撑即将上线的 GPT-5 等更庞大的模型。